Department of Computer Science and Information Systems. The University
of Hong Kong Pokfulam, Hong Kong.
Gigabit Ethernet is widely available and is becoming the commodity of the next generation LAN [3]. Gigabit Ethernet appears to be an ideal solution to the increasing demands placed on today's high-end server that operates at gigahertz clock rate. However, installing a Gigabit Ethernet adapter in an existing server generally won't yield the 10-fold performance boost over a fast Ethernet adapter. To achieve high performance, the communication software needs to minimize the protocol-processing overheads and resource consumption.
With the introduction of low-latency messaging systems, such as Active Messages (AM) [24], Fast Messages (FM) [16], BIP [17], PM [18], U-Net [25], and GAMMA [6], protocol-processing overheads induced in communication have been significantly reduced. Some of these messaging systems achieve low latency by pinning down a large area of memory as the send or receive buffers. This avoids the delay caused by the virtual memory system for mapping virtual address to physical address during the messaging stages. Such approach trades memory space for shorter communication latency. However, without a good flow control mechanism or an efficient higher level protocol, this type of messaging systems is usually not scalable. It may experience poor performance when a large number of concurrent communication channels need to be established during the program execution, because of the inefficient memory utilization. Some other messaging systems adopted the user-level approach, which allows moving data from user space to the network adapter without switching contexts or additional memory copy. This type of communication software may achieve shorter latency, however memory copy is sometimes inevitable to maintain the message integrity while extending the messaging system to develop a higher communication layer with more functions, such as the reliable support. Moreover, to avoid violating the OS protection mechanisms, these user-level solutions are usually restricted to have only one process using the communication system on a single host machine.
Besides the performance issue, programmability is also an essential goal for the design of communication subsystem. Adequate programmability means that programmer's parallel algorithm can be easily translated to parallel code through the provided API. This requres the provision of a communication abstraction model which can be used to depict various inter-process communication patterns exhibited during the program execution and a powerful yet ease-to-learn API for translating such patterns to program code. Many existing low-latency communicationpackages provide good performance, but they neglect the need of a simple and user-friendly API. Most of them just form their own programming interface, using complex data structures and syntax, thus making them difficult to use. They usually lack a good abstraction model for the high-level description of the communication algorithm, or an API that copes with the abstraction model and is easy to learn. For example, neither Active Messages nor Fast Messages provide standard set of operations like those used in the widely accepted MPI [14]. A message has to be received within a handler routine, which is specified by the send function. Programs are more easily prone to errors, especially for those with many communication partners and having multiple ways of message handling.
In this paper, we present a high-performance communication system, Directed Point (DP), with the goals of achieving high performance and good programmability. The DP abstraction model depicts the communication channels built among a group of communicating processes. It supports not only the point-to-point communication but also various types of group operations. Based on the abstraction model, all inter-process communication patterns are described by a directed graph. For example, a directed edge connecting two endpoints represents a unidirectional communication channel between a source process and a destination process. The application programming interface (API) of DP combines features from BSD Sockets and MPI to facilitate the peer-to-peer communication in a cluster. DP API preserves the syntax and semantics of traditional UNIX I/O interface by associating each DP endpoint with a file descriptor. All messaging operations must go through the file descriptor to send or receive messages. With the file descriptor, a process can access the communication system via traditional I/O system calls.
To achieve high performance with the consideration of generation scalability, DP is designed and implemented based on a realistic yet flexible cost model. The cost model captures the overheads incurred in the host machine and network hardware. It is used as a tool for both communication algorithm design and performance analysis. We consider data communication via the network as an extension to the concept of memory hierarchy. Thus, we abstract the communication event by means of local and remote data movements, and express all parameters by their associated cost functions. This model helps the design of DP adapt well to various speed gaps in processor, memory, I/O bus, and network technologies, thus achieves good generation scalability.
Based on the cost model, we propose various optimizing techniques, namely directed message (DM), token buffer pool (TBP), and light-weight messaging call. DP improves the communication performance by reducing protocol complexity through the use of DM, by reducing the intermediate memory copies between protocol layers through the use of TBP, and by reducing the context-switching and scheduling overhead through the use of light-weight messaging calls. DP allocates one TBP for each DP endpoint. It requires no common dedicated global buffers for storing incoming messages in the kernel space or user space. When a process needs to maintain a large number of simultaneous connections or multiple parallel programs are in execution, separate control of receive buffers avoids locking overhead. Moreover, the memory resource in a host machine can be efficiently utilized and can eliminate unnecessary memory copy as the message buffers are mapped to both the kernel space and the user space.
We have implemented DP for various networks, including Intel EEPro Fast Ethernet, Digital 21140A Fast Ethernet, Packet Engine G-NIC II Gigabit Ethernet, and FORE PCA-200E ATM. DP effectively streamlines the communication steps and reduces protocol-processing overhead, network buffer management overhead and process-kernel space transition overhead. The performance test of Directed Point shows low communication latency and high bandwidth as well as less memory resource consumption.
For the rest of the paper, we first introduce the Directed Point abstraction model in Section 2. Section 3 describes the architectural background and assumptions of our communication model, together with a layout of all model parameters. The performance enhancement techniques inspired by this cost model are discussed in Section 4. In Section 5, we evaluated and discussed the performance characteristics of two DP implementations, which are based on two different Ethernet-based technologies. In Section 6, we briefly studied and compared DP with other Gigabit communication packages, and finally the conclusions are given in Section 7.
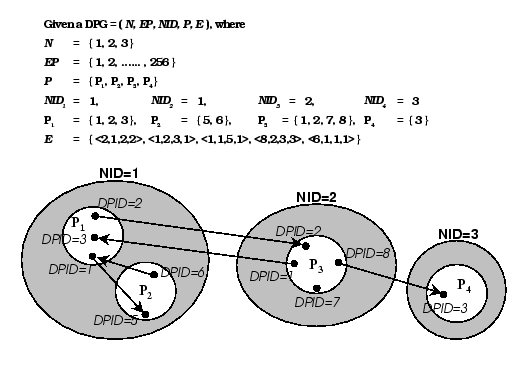
The Directed Point abstraction model [12] provides programmers with a virtual network topology among a group of communicating processes. The abstraction model is based on a directed point graph (DPG), which allows users to statically depict the communication pattern, and it also provides schemes to dynamically modify the pattern during the execution. All inter-process communication patterns can be described by a directed graph, with a directed edge connecting two endpoints representing a unidirectional communication channel between a source process and a destination process. The formal definition of the DPG is given below:
Let DPG = (N, EP, NID, P, E), where N, EP, NID, P and E are:
Figure 1 shows the corresponding DP graph
of the given example. A white circle represents a communication process,
each vertex represents a communication endpoint, and a directed edge specifies
a unidirectional communication channel between a pair of DP endpoints.
From the function NID, we know that process 1 and process 2 are executed
in node 1. There are five communication channels between these processes.
For example, the channel <1,1>![]() <5,1>
is from the endpoint 1 of process 1 to the endpoint 5 of process 2.
<5,1>
is from the endpoint 1 of process 1 to the endpoint 5 of process 2.
 |
While capturing the design features presented above, the programming interface of DP is also simple to use. It follows the peer-to-peer communication model, providing functions such as dp_open(), dp_read() and dp_write(), which are analogous to the open(), read() and write() system calls used in the traditional BSD Socket communication. A summary of the DP API is shown in Table 1.
| New System Call | |
| int dp_open(int dpid) | create a new DP endpoint |
| User-level Function Calls | |
| int dp_read(int fd, char **address) | read an arrived DP message |
| int dp_mmap(int fd, dpmmap_t *tbp) | associate a token buffer pool (see Section 4.2) with a DP endpoint |
| void dp_close(int fd) | close the DP connection |
| Light-weight Message Calls | |
| int dp_write(int fd, void *msg, int len) | send a DP message |
| int dp_fsync(int fd, int n) | flush n DP messages in the token buffer pool |
| void dp_target(int fd, int nid, int dpid) | establish a connection with the target endpoint |
The DP API Layer consists of system calls and user level function calls, which are operations provided to the users to program their communication codes.
To provide better programmability, DP API preserves the syntax and semantics of traditional UNIX I/O interface by associating each DP endpoint with a file descriptor, which is generated when a DP endpoint is created. All messaging operations must go through the file descriptor to send or receive messages. The communication endpoint is released by closing the file descriptor. With the file descriptor, a process can also access the communication system via traditional I/O system calls.
The DP API provides a familiar user interface to application programmers, which can reduce the burden of learning new API. Moreover, programmers need not deal with the IP address and the port numbers of computing nodes anymore. Instead, the NIDs and DPIDs are used to specify every communication endpoint. By constructing the communication pattern in the form of a DP graph as illustrated above, one can easily translate the DP graph into application code without any knowledge of the IP or hardware address information.
Many other low-latency communication packages provide good performance, but they neglect the need of a simple and user-friendly API. Most of them just form their own programming interface, using complex data structures and syntax, thus making them difficult to use. For example, neither Active Messages nor Fast Messages provide explicit receive operations like those used in BSD Sockets. A message has to be received within a handler routine, which is specified by the send function. Programs are more easily prone to errors, especially for those with many communication endpoints and multiple ways of message handling. A programmer may specify the wrong handler, causing the program to exhibit unexpected behaviors. Similarly, GAMMA [6] also allows users to receive messages within a handler routine only. However, instead of putting the handler address into one of the send function arguments, the handler has to be specified at a special function, which is used to establish a communication channel between two GAMMA endpoints before communication takes place. Moreover, a GAMMA communication channel is specified using a 6-tuple: {local node ID, local process ID, local port ID, dest node ID, dest process ID, dest port ID}. This is more complicated than DP, where we use a 4-tuple description.
U-Net [25] adopts a peer-to-peer model with explicit user commands for sending and receiving messages between two endpoints through a channel. Although the send and receive operations only require users to specify the local endpoint and channel to be used, setting up endpoints and channels can be tedious. Programmers have to open a U-Net device, and use the returned file descriptor to create an endpoint. A channel is then formed by using the destination address of the U-Net device as input. Each procedure requires an explicit function call, reducing the user-friendliness of U-Net. On the other hand, the communication channel established in BIP [17] can be described using a 4-tuple notation {local node ID, local tag ID, dest node ID, dest tag ID}, just like DP does. However, a routing program and a configuration program needs to be executed before a user application is run, so as to determine the network topology and the number of nodes to be used for the application.
The programming interface of PARMA [13] is closely resembled to the BSD Socket interface. Therefore it adopts a client-server model and makes use of Unix system calls such as bind(), accept(), listen(), read() and write() for network communication. The extra socket layer and the system calls introduce extra overhead. In comparison, DP does not contain such a socket layer and hence eliminates this software overhead. Moreover, DP adopts a peer-to-peer model like the MPI, eliminating the need to perform binding and listening between endpoints of a communication channel. However, it is easy to build up this socket layer on top of DP in order to cope with user convenience and program compatibility issues [4].
A model, in general, is an abstract view of a system or a part of a system, obtained by removing the details in order to allow one to discover and work with the basic principle [10]. However, the diversity of computer architectures and the complexity of parallel applications require models to be used at various levels of abstraction that are highly related to the application characteristics. Such models should be developed for the relevant characteristics of the applications together with the characteristics of the architecture. Hence, with such a diverged domain of applications designated for parallel and cluster computing, e.g. regular and irregular problems, a simple, rigid model could not serve our needs.
In general, existing parallel models that focus on message-passing architecture, which include abstract architecture models (e.g. LogP [9], BSP [22]) and communication models (e.g. Postal [1]), usually assume reliable network, such that they treat sending a message as a send-and-forget [1] event. They also assume fully connected network with the exact architecture of the underlying communication network ignored. Communication is based on point-to-point semantics, with the latency between any pair of processors roughly the same time for all cases. These models provide an abstract ground for development. However, they have some drawbacks.
Under BSP model, parallel algorithm is portrayed as a sequence of parallel supersteps, which consists of a sequence of local computations plus any message exchange and follows by a global synchronization operation. With this restricted programming style, the overall usage may be affected. For the LogP model, it tends to be more network-oriented and simple. It uses four parameters to capture the cost associated with the communication events without limits to any programming style. However, its parameters neglect factors related to message size, communication load, and contention issue, which influence the communication latency in a large degree in real networks. An interesting feature of LogP model is the idea of finite capacity of the network, such that no more than certain amount of messages can be in transit from any processor or to any processor at any time, and any attempts to exceed the limit will stall the processor. However, the model does not provide any clear idea on how to quantify, avoid and take advantage of this information in algorithm design. The Postal model is similar to LogP model, with the exception of expressing the network more abstractly. The system is characterized by two parameters only, and this effectively reduces the dimension of analysis. Therefore, it facilitates communication analysis rather than for performance studies.
Most of the above drawbacks come from the tradeoff between simplicity and accuracy. The uses of those parameters are subjected to the target level of abstraction together with the application characteristics that we are going to work on. For instance, using a simple latency parameter may be good enough to capture the cost of the point-to-point communication, but is too simple for explaining the many-to-one or many-to-many issues, where contention problem may affect the communication performance.
In our model, a cluster is defined as a collection of autonomous machines that are interconnected by a switch-based network. We assume it is a packet-switched, pipelined network, and operates in a full-duplex configuration. Buffers are provided in the switches for temporary buffering, but the amount of buffers is assumed to be finite. All cluster nodes communicate via this switch-based network and assume to have the same local characteristics, such as computation power, memory hierarchy, operation system supports, and communication hardware. In our study, we assume that each node is equipped with one set of input and output channels, that is, it can simultaneously send and receive one data packet in one communication step.
A cost model is associated with our model parameters, which is focusing on the costs induced by moving data around, both locally and remotely. We consider data communication via the network as an extension to the concept of memory hierarchy, such as a movement from the remote memory region to the local memory region. So there may have two types of data movements involved in the parallel computation or in a communication event: a) remote data transfer and b) local data transfer. Our model intends to capture the cost of point-to-point communication and also contention overheads in various collective operations. Emphasis has also been made on the derivation of our model parameters by software approach, which is the key to the whole analytical process.
 |
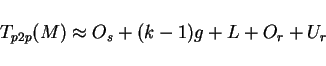 |
(1) |
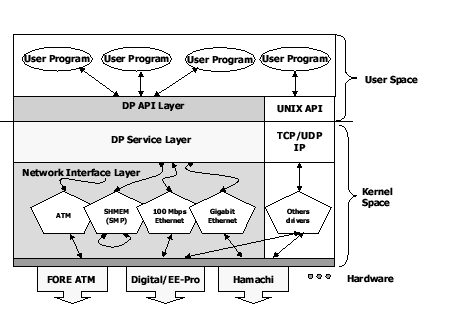 |
The DP API Layer consists of system calls and user level function calls, which are operations provided to the users to program their communication codes. Full discussion of the DP API is provided in Section 2.
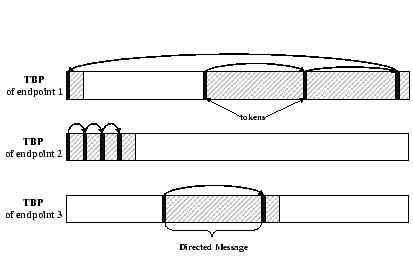 |
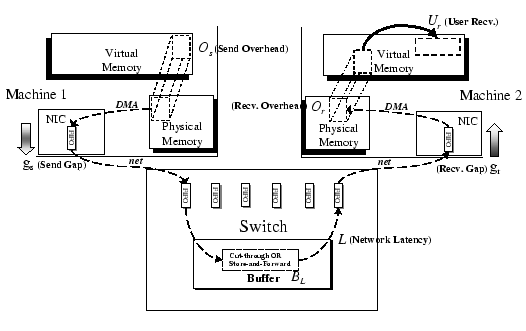
We use our Gigabit Ethernet (GE) implementation as an example to illustrate the data movement journey adopted in DP. The Hamachi GE NIC uses a typical descriptor-based bus-master architecture [2]. Two statically allocated fixed-size descriptor rings, namely, the transmit (Tx) and receive (Rx) descriptor rings. Each descriptor contains a pointer to the host physical memory that stores incoming and outgoing messages. Figure 5 shows the messaging flow with respect to different components in DP using such descriptor-based network interface controller.
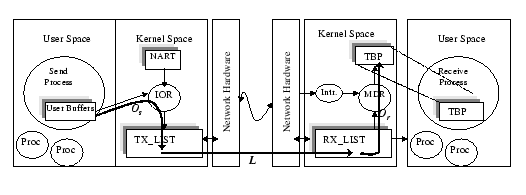 |
When the packet arrives, an interrupt signal is triggered by the network adapter. The interrupt handler calls the Message Dispatcher Routine (MDR) - a service in the DP Service Layer, examines the header of packet, locates the destination TBP based on the information stored in arrived DM, and copies the incoming message to a buffer at TBP. Since TBP is accessible by both kernel and user processes, the incoming message can be directly used by the user program.
DP allocates one TBP whenever a new DP endpoint is opened by the user program. It requires no common dedicated system buffers (such as socket buffer in BSD Socket) for storing incoming messages. Separate control of receive buffer avoids locking overhead when a process needs to maintain a large number of simultaneous connections. Moreover, the memory resource in a server can be efficiently utilized. The amount of memory needed is proportional to the number of endpoints created in the applications. The total memory consumption is roughly the same as the size of total incoming packets because of the use of variable-length token buffer.
In summary, DP improves the communication performance in the following ways: (1) by reducing protocol complexity through the use of DM, (2) by reducing the intermediate memory copies between protocols through the use of TBP, and (3) by reducing the context-switching and scheduling overhead through the use of light-weight messaging calls. Other low-latency messaging systems have also adopted similar performance enhancement techniques but using different strategies. For example, AM eliminates intermediate buffering at the receiving end by pre-allocating storage for the arriving data in the user program. AM reduces the scheduling overhead through the use of receive handlers, which interrupt the executing process immediately upon message arrival. GAMMA, an AM variant using Ethernet-based network, also inherited these techniques. It bypasses the TCP/IP protocol overhead and reduces the context-switching overhead through a small set of light-weight system calls and a fast interrupt path. Moreover, to ensure that messages can be moved directly from the adapter to the receiver buffer, it requires the user to explicitly pin down the receiver buffer before initiating the associated communication event. It also reduces the memory copy in the send operation, by moving the messages right away to the adapter's FIFO queue, without intermediate buffering in kernel space. On the other hand, FM also eliminates excess data copying, as the FM interface uses message streams to eliminate the need to marshal and un-marshal the messages to be communicated. Users do not need to perform explicit memory copy to assemble a message to be sent, even the message contents are not contiguous in the user memory. However, as mentioned, the handler approach for receiving messages, as adopted by these three packages, lacks programmability and portability as compared with DP.
For U-Net on ATM, performance is enhanced through removing the kernel from the critical path of sending and receiving messages. However, due to the absence of network co-processor on the Ethernet adapters, U-Net on FE has to go through the kernel space for OS protection. To reduce memory copy, it pre-allocates and pins down a fixed memory segment, called U-Net endpoint, which is structured to form a complex virtual network interface. During communication, users have to deposit and retrieve messages through this endpoint structure. Therefore, users are compelled to allocate a large memory segment right at the beginning, which is large enough to sustain the maximum load, but could only be released at the end of the application. Finally, PARMA aims at designing a greatly simplified protocol (known as PRP protocol) as compared to TCP/IP. By neglecting flow control and error recovery, PARMA succeeds in reducing the protocol overhead. However, the implementation of a Socket layer introduces certain amount of system call overhead.
To review the performance issues related to high-speed communication on clusters, we have performed a series of benchmark tests on these clusters. To achieve beyond-microsecond precision, all timing measurements are calculated by using the hardware time-stamp counters in the Intel Pentium processors. If applicable, all data presented in this section are derived from a statistical calculation with multiple iterations of the same benchmark routine. Each test is conducted with at least 200 iterations with the first and last 10% of the measured timing excluded. Only the middle 80% of the timings are used to calculate the average.
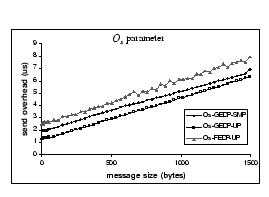 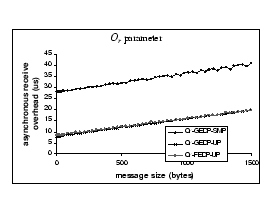
a) Send overhead b) Asynchronous receive overhead
|
The ![]() parameter reflects the time used by the host CPU to initiate the transmission
while performing the dp_write() operation. Figure 6(a)
shows the cost associated with the dp_write() operation. The 500MHz
Xeon processor slightly performs better than the 450MHz Pentium III processor.
We observe that the penalty of preserving the traditional Unix I/O abstraction
in DP is the use of one-copy semantic in the send operation. However, by
adoption of the Light-weight Messaging Call and the Directed Message protocol,
we manage to minimize the send overhead and achieve good performance in
driving the Gigabit network. For example, the cost to send a full-size
Ethernet packet is less than 7
parameter reflects the time used by the host CPU to initiate the transmission
while performing the dp_write() operation. Figure 6(a)
shows the cost associated with the dp_write() operation. The 500MHz
Xeon processor slightly performs better than the 450MHz Pentium III processor.
We observe that the penalty of preserving the traditional Unix I/O abstraction
in DP is the use of one-copy semantic in the send operation. However, by
adoption of the Light-weight Messaging Call and the Directed Message protocol,
we manage to minimize the send overhead and achieve good performance in
driving the Gigabit network. For example, the cost to send a full-size
Ethernet packet is less than 7 ![]() under the SMP OS, while the theoretical speed in delivering such an Ethernet
packet under Gigabit performance is around 12.3
under the SMP OS, while the theoretical speed in delivering such an Ethernet
packet under Gigabit performance is around 12.3 ![]() .
With the SMP mode, there is an extra 0.5
.
With the SMP mode, there is an extra 0.5 ![]() overhead associated with it due to the use of locks for integrity control.
overhead associated with it due to the use of locks for integrity control.
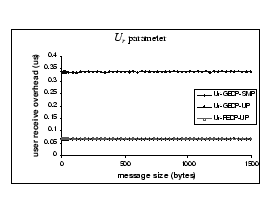
When examining on the ![]() parameter - Figure 6(b), we find that SMP
OS has an extra 20
parameter - Figure 6(b), we find that SMP
OS has an extra 20 ![]() overhead added on to this parameter, while both GEDP-UP and FEDP-UP have
similar performance.
overhead added on to this parameter, while both GEDP-UP and FEDP-UP have
similar performance.
 |
Since the token buffer pool is accessible by the kernel and user process,
the receiving process can simply check on this TBP for picking up and consuming
the messages. As these are done in the user space, no kernel events such
as block and wake-up signal are needed. Figure 6(c)
shows the ![]() cost of picking up a Directed Message directly from the TBP without any
memory copy cost or system call overhead. Constant overheads, 0.34
cost of picking up a Directed Message directly from the TBP without any
memory copy cost or system call overhead. Constant overheads, 0.34 ![]() ,
0.06
,
0.06![]() and 0.07
and 0.07 ![]() were measured for GEDP-SMP, GEDP-UP, and FEDP, respectively.
were measured for GEDP-SMP, GEDP-UP, and FEDP, respectively.
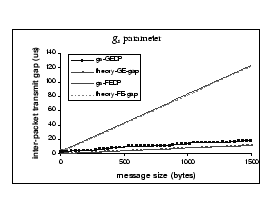
Figure 6(d), (e) and (f) show three other
network-dependent parameters, they are the network latency L, inter-packet
transmit gap ![]() and inter-packet receive gap
and inter-packet receive gap ![]() .
To justify their relative performance, all parameters are compared with
their theoretical limits. Looking at the FEDP data, we find that with modern
PC or server hardware and low-latency communication system, we are able
to drive the Fast Ethernet network with its full capacity. For example,
the measured
.
To justify their relative performance, all parameters are compared with
their theoretical limits. Looking at the FEDP data, we find that with modern
PC or server hardware and low-latency communication system, we are able
to drive the Fast Ethernet network with its full capacity. For example,
the measured ![]() and
and ![]() for m = 1500 bytes is 122.75
for m = 1500 bytes is 122.75 ![]() and 122.84
and 122.84 ![]() ,
while the theoretical gap is 123.04
,
while the theoretical gap is 123.04 ![]() .
This means that the performance of the host machine is faster than the
speed of the Fast Ethernet network in all aspects. For the Gigabit Ethernet,
due to the 10-fold increase in network speed, limitations within the host
machine start to pop up. The graph with
.
This means that the performance of the host machine is faster than the
speed of the Fast Ethernet network in all aspects. For the Gigabit Ethernet,
due to the 10-fold increase in network speed, limitations within the host
machine start to pop up. The graph with ![]() -GEDP
data (Figure 6e) shows that the network
adapter cannot transmit data in full gigabit performance. The measured
-GEDP
data (Figure 6e) shows that the network
adapter cannot transmit data in full gigabit performance. The measured ![]() for m = 1500 bytes is 18.76
for m = 1500 bytes is 18.76 ![]() but the theoretical gap is 12.3
but the theoretical gap is 12.3 ![]() .
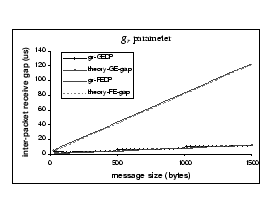
We have performed some preliminary investigation on this aspect, and the
problem seems related to the PCI performance, even though our Dell server
is coupled with a 64bit 33MHz PCI bus. A similar pattern also appears in
the
.
We have performed some preliminary investigation on this aspect, and the
problem seems related to the PCI performance, even though our Dell server
is coupled with a 64bit 33MHz PCI bus. A similar pattern also appears in
the ![]() -GEDP
data, but is not as significant as that of the
-GEDP
data, but is not as significant as that of the ![]() parameter. The measured
parameter. The measured![]() for m = 1024 bytes is 10.6
for m = 1024 bytes is 10.6 ![]() but the theoretical gap is 8.5
but the theoretical gap is 8.5 ![]() .
Part of the reason may be due to the difference in read and write performance
of the PCI bus.
.
Part of the reason may be due to the difference in read and write performance
of the PCI bus.
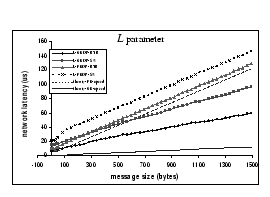
Lastly, when look at the L parameter, the calculated network
latency of the GEDP with back-to-back connection is 6.9 ![]() for a 1-byte message, while the network latency of the FEDP with back-to-back
connection is 9.9
for a 1-byte message, while the network latency of the FEDP with back-to-back
connection is 9.9 ![]() for the same size message. We observe that the add-on latency by the GE
hardware is much higher than that of the FE, when we compare the theoretical
wire delay for the smallest packet size of the GE and FE, which are 0.67
for the same size message. We observe that the add-on latency by the GE
hardware is much higher than that of the FE, when we compare the theoretical
wire delay for the smallest packet size of the GE and FE, which are 0.67 ![]() and 6.7
and 6.7 ![]() respectively. For example, in Figure 6(d),
the gaps between the network latency measurements with FE back-to-back
and FE through switch, and between FE back-to-back and theoretical FE speed
are almost constant, while the corresponding gaps on the GE platform seem
to be increasing with the message size.
respectively. For example, in Figure 6(d),
the gaps between the network latency measurements with FE back-to-back
and FE through switch, and between FE back-to-back and theoretical FE speed
are almost constant, while the corresponding gaps on the GE platform seem
to be increasing with the message size.
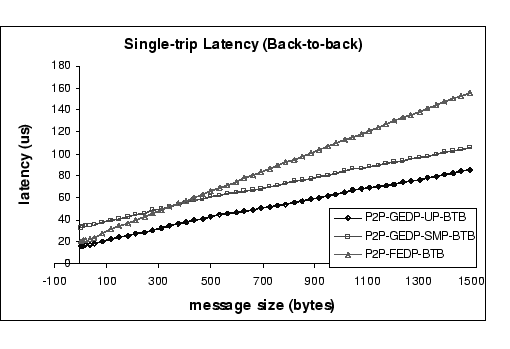
Figure 7 shows the latency results
of the two DP implementations. To avoid add-on latencies from the switches,
we connect two nodes back-to-back and measure their single-trip latencies.
The GEDP-UP achieves single-trip latency of 16.3 ![]() for sending 1-byte message, while GEDP-SMP achieves 33.4
for sending 1-byte message, while GEDP-SMP achieves 33.4![]() and FEDP achieves 20.8
and FEDP achieves 20.8 ![]() respectively. From the above analysis, we obtain a set of performance metrics,
which clearly delineate the performance characteristics of our DP implementations.
In summary, the host/network combination of the FEDP implementation has
the performance limitation on its network component. This is being observed
by comparing the
respectively. From the above analysis, we obtain a set of performance metrics,
which clearly delineate the performance characteristics of our DP implementations.
In summary, the host/network combination of the FEDP implementation has
the performance limitation on its network component. This is being observed
by comparing the ![]() ,
, ![]() ,
and
,
and ![]() parameters with the
parameters with the ![]() ,
, ![]() and L parameters. And since their performance characteristics satisfy
this condition,
and L parameters. And since their performance characteristics satisfy
this condition,![]() ,
we can directly adopt the previous defined point-to-point communication
cost (
,
we can directly adopt the previous defined point-to-point communication
cost (![]() )
whenever we want to evaluate on its long message performance. Moreover,
the host/network combination of the GEDP implementation has the performance
limitation not falling on the network component. For instance, the
)
whenever we want to evaluate on its long message performance. Moreover,
the host/network combination of the GEDP implementation has the performance
limitation not falling on the network component. For instance, the ![]() parameter is higher than the
parameter is higher than the ![]() and
and ![]() parameters for both GEDP-SMP and GEDP-UP, which means the performance bottleneck
may fall on this region. Therefore, when predicting their long message
performance, new point-to-point communication cost formulae are required.
For example, the new cost formula for predicting the one-way point-to-point
communication cost of the GEDP-UP implementation becomes:
parameters for both GEDP-SMP and GEDP-UP, which means the performance bottleneck
may fall on this region. Therefore, when predicting their long message
performance, new point-to-point communication cost formulae are required.
For example, the new cost formula for predicting the one-way point-to-point
communication cost of the GEDP-UP implementation becomes:
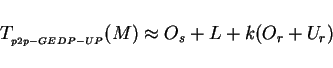 |
(2) |
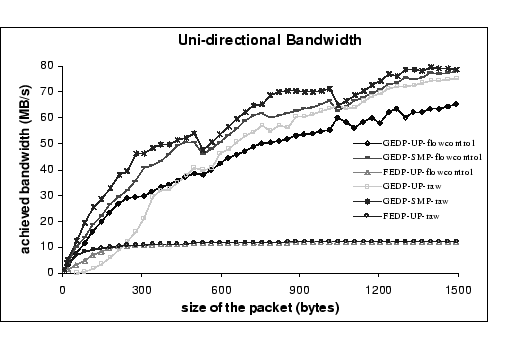 |
With flow control on, the FEDP performs as good as the raw performance for medium to large-sized messages. But for the GEDP, the higher protocol overhead does affect the overall performance, especially under the UP kernel mode. Our result shows that under the SMP mode, the maximum achieved GEDP bandwidth with flow control is 77.8 MB/s, with an average drop of 3.4% performance for the data ranged between 1K and 1.5K when compared with the raw speed. While for the performance under UP mode, the maximum achieved bandwidth with flow control is 65.2 MB/s and the average performance drop is 13% of the raw speed for the same data range. This further supports our argument that the performance of GEDP-UP is more susceptible to software overheads.
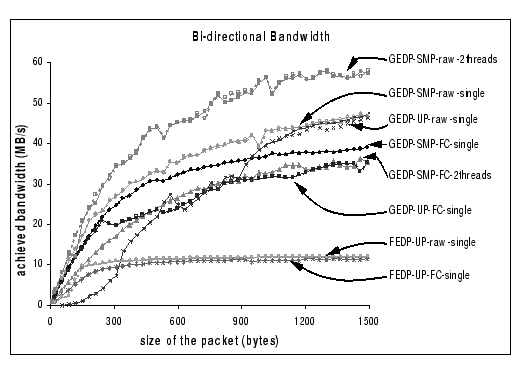 |
For the GEDP, the best bi-directional performance is observed to be about 58 MB/s per process, which is measured on raw DP using multi-thread mode on SMP kernel. Comparing with the uni-directional bandwidth, we have a performance loss of 22 MB/s. We attribute this performance loss to the contention on the PCI bus as there are concurrent DMA transfers to and from the host memory. When compared with the single thread mode on GEDP-SMP and GEDP-UP, which only achieve 47 MB/s per process, we believe that the software overhead induced in the concurrent send and receive operations is the main cause of this performance loss. Therefore, with the add-on flow control (FC) layer that adds more software overhead, it is sensible to see that all GEDP-FC performance suffers more. However, it is surprising to find that the bi-directional performance of GEDP-SMP-FC with multiple thread support is worse than the single thread mode. This performance difference is coming from the extra memory contention and synchronization needed in accessing shared data structures on the reliable layer as both threads are concurrently updating those shared information. Finally, similar to the conclusion as appeared in the uni-directional benchmark, the performance of the FEDP on bi-directional communication has achieved a near-optimal result, which attains 12.16 MB/s per process on the raw bandwidth, and 11.7 MB/s per process with the add-on flow control support.
Fast Messages 2.x (FM 2.x) [11] is
the core communication layer found inside the High Performance Virtual
Machine (HPVM) package [5]. It has been
implemented on Myrinet and Giganet, and runs on Windows NT. To send a 4-byte
message, the measured latency is 9.63 ![]() on Myrinet and 14.7
on Myrinet and 14.7![]() on Giganet. For sending a 16-Kbyte message, the bandwidth reaches 100.53
MB/s on Myrinet and 81.46 MB/s on Giganet. The user interface of FM 2.x
is quite different from DP. In DP, the API for the send and receive operations
is quite straightforward, just involving one send and one receive function
respectively. However, in FM 2.x, the send operation involves three functions
- FM_begin_message(),
FM_send_piece() and FM_end_message(),
and the receive operation involves 2 functions - FM_extract() and
FM_receive(),
which may cause inconvenience for the users.
on Giganet. For sending a 16-Kbyte message, the bandwidth reaches 100.53
MB/s on Myrinet and 81.46 MB/s on Giganet. The user interface of FM 2.x
is quite different from DP. In DP, the API for the send and receive operations
is quite straightforward, just involving one send and one receive function
respectively. However, in FM 2.x, the send operation involves three functions
- FM_begin_message(),
FM_send_piece() and FM_end_message(),
and the receive operation involves 2 functions - FM_extract() and
FM_receive(),
which may cause inconvenience for the users.
The GigaE PM [18] has been designed and
implemented for parallel applications on clusters of computers on Gigabit
Ethernet. It provides not only a reliable high bandwidth and low latency
communication function, but also supports existing network protocols such
as TCP/IP. By adopting a technique similar to the U-Net approach, PM provides
a low-latency communication path through a virtual network object. This
virtual network object encapsulates all the data structures needed to maintain
a virtual channel between processes of the same parallel application, which
include the fixed-size send and receive buffers and the associated queue
structures. In its first implementation, it achieved 48.3 ![]() round-trip latency and 56.7 MB/s bandwidth on Essential Gigabit Ethernet
NIC using Pentium II 400 MHz processor. GigaE PM II [19]
has been implemented on Packet Engines G-NIC II for connecting Compaq XP-1000
workstations, each with 64-bit Alpha 21264 processor running at 500 MHz.
The performance results show a 44.6
round-trip latency and 56.7 MB/s bandwidth on Essential Gigabit Ethernet
NIC using Pentium II 400 MHz processor. GigaE PM II [19]
has been implemented on Packet Engines G-NIC II for connecting Compaq XP-1000
workstations, each with 64-bit Alpha 21264 processor running at 500 MHz.
The performance results show a 44.6![]() round-trip time for an eight-byte message. XP1000's four 64-bit CPU data
buses, which support a 2.6 GB/s aggregate bandwidth, help GigaE PM II achieve
98.2 MB/s bandwidth for message length 1,468 bytes.
round-trip time for an eight-byte message. XP1000's four 64-bit CPU data
buses, which support a 2.6 GB/s aggregate bandwidth, help GigaE PM II achieve
98.2 MB/s bandwidth for message length 1,468 bytes.
Virtual Interface Architecture (VIA) [23] is a novel communication architecture for clusters. It adopts the user-level communication paradigm and tries to standardize the interface for high-performance network technologies such as Gigabit networks. VI Architecture reduces network-related system processing overhead by creating the illusion of a dedicated network interface to multiple application programs simultaneously. Each VI represents a communication endpoint. Pairs of VIs can be logically connected to support point-to-point data transfer. M-VIA is a prototype software implementation of the VIA for Linux [15]. It supports the Fast Ethernet DEC Tulip chipsets as well as Packet Engines GNIC-I and GNIC-II Gigabit Ethernet cards. It is implemented as a set of loadable kernel modules and a user level library, and provides software doorbells with a fast trap for legacy hardware. The design of M-VIA adopts a highly modular approach similar to DP. M-VIA further abstracts the Kernel Agent defined in VIA specification into the M-VIA Kernel Agent and one or more M-VIA Device Drivers which are hardware dependent. Currently the evolution version of M-VIA, MVIA-2, is still under development. It will have much better support for high performance networks such as Giganet, Servernet II and Myrinet.
Our messaging mechanisms significantly reduce the software overheads
induced in the communication, as well as optimizing the memory utilization
with an efficient buffer management scheme. Our implementation of the Directed
Point communication system on two Ethernet-based networks achieves remarkable
performance, e.g. the single-trip latency for sending 1-byte message is
16.3 ![]() and 20.8
and 20.8 ![]() on the Gigabit Ethernet and Fast Ethernet network respectively. With a
standard PC, 97% of the Fast Ethernet network bandwidth is available to
user applications, that corresponds to the achievable bandwidths of 12.2
MB/s and 24.32 MB/s for the uni-directional traffic and bi-directional
traffic respectively.
on the Gigabit Ethernet and Fast Ethernet network respectively. With a
standard PC, 97% of the Fast Ethernet network bandwidth is available to
user applications, that corresponds to the achievable bandwidths of 12.2
MB/s and 24.32 MB/s for the uni-directional traffic and bi-directional
traffic respectively.
Although DP achieves 63.6% of the Gigabit Ethernet bandwidth, (i.e.
79.5 MB/s), the performance evaluation result shows us that there are still
rooms for us to further improve its performance, especially on the bi-directional
bandwidth which is involved in many collective operations. For example,
based on our communication model, it shows that the memory copies on the ![]() and
and ![]() parameters affect the overall performance in the Gigabit Ethernet network.
parameters affect the overall performance in the Gigabit Ethernet network.
The secondary goal of DP is to achieve good programmability. A speedy communication system on its own does not guarantee to provide the efficient solutions to cluster applications. To address the programmability issue, DP provides an abstraction model and an API that has Unix-like I/O syntax and semantics. With the abstraction model, users can express those inter-process communication patterns on a directed point graph. This cleanly depicts the runtime system requirement of the target application and allows users to optimize their design strategies, e.g. allocating appropriate number of endpoints to realize this communication pattern. By providing an Unix-like I/O API, DP assists users in migrating their applications to the new environment, and facilitates the implementation of high-level communication libraries, e.g. MPI.
Indeed, the advance in the network technology has made the network capable of delivering packets in Gigabit speed or even higher. However, having the capability to deliver the packets in higher speed does not guarantee to achieve optimal performance while performing more complicated communication operations, such as many-to-one and many-to-many communications [21], since contention problems can happen in host node, network link and switch. The increasing growth of the network performance has stressed the need of a better resource utilization and system scalability on the design of contention-free collective communication algorithm.
This document was generated using the LaTeX2HTML translator Version 99.2beta8 (1.42)
Copyright © 1993, 1994, 1995, 1996,
Nikos
Drakos, Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross
Moore, Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -no_subdir -split 0 -show_section_numbers /home/atctam/documents/FGCS/dp-fgcs.tex
The translation was initiated by Anthony Tam on 2001-02-12