|
|
© Systems Research Group, Department of Computer Science, The University of Hong Kong. |
| |
|
© Systems Research Group, Department of Computer Science, The University of Hong Kong. |
|
Research >> JUMP Homepage · JUMP · Research Main ** Main · People · Publications · Facilities · Links |
|
The JUMP Software System:
|
|
Download: Interested persons
please click here to fill in the
information for downloading the JUMP source
code. |
|
Summary: JUMP is a page-based software DSM system for clusters of PCs or workstations. It adopts the Migrating-Home Protocol (MHP) to implement Scope Consistency (ScC), both of which improve the DSM performance by reducing the amount of data traffic within the network. Currently, JUMP is implemented as a user-level C library on top of UNIX, and is able to run on homogeneous clusters of PCs or workstations with SunOS or Linux operating system. We also propose an extension of JUMP, namely JUMP-DP, which makes use of the low-latency Socket-DP communication support.
|
|
Software DSM and Memory Consistency Models: Distributed shared memory (DSM) is a parallel programming paradigm, which provides programmers an abstraction that the memory among different machines are shared, even though they are actually distributed physically (Figure 1). Programmers need not deal with the actual data communication (as message passing paradigms like MPI do) in their programs; the underlying DSM system will do the job for the programs. Thus DSM programs just access the shared memory variables the same way as local variables do.
Although DSM gives users an impression that all processors are sharing a unique piece of memory, in reality each processor can only access the memory it owns. Therefore the DSM must be able to bring in the contents of the memory from other processors when required. This gives rise to multiple copies of the same shared memory in different physical memories. The DSM has to maintain the consistency of these different copies, so that the any processor accessing the shared memory should return the correct result. A memory consistency model is responsible for the job. Intuitively, the read of a shared variable by any processor should return the most recent write, no matter this write is performed by any processor. The simplest solution is to propagate the update of the shared variable to all the other processors as soon as the update is made. This is known as sequential consistency (SC) [1]. However, this can generate an excessive amount of network traffic since the content of the update may not be needed by every other processor. Therefore certain relaxed memory consistency models are developed (Figure 2). Most of them provide synchronization facilities such as locks and barriers, so that shared memory access can be guarded to eliminate race conditions. When used properly, these models guarantee to behave as if the machines are sharing a unique piece of memory. Here shows some of the most popular memory consistency models:
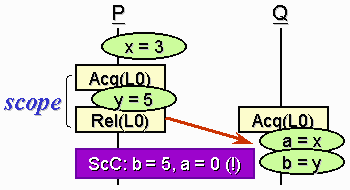
DSM performance is always a major concern. The first DSM system, IVY, uses SC but performance is poor due to excessive data communication in the network. This major performance bottleneck is relieved by later systems, which use other relaxed models to improve efficiency. For example, Munin made use of the weak Eager Release Consistency (ERC) [2] model. TreadMarks (TMK) [3] went a step further, using the weaker Lazy Release Consistency (LRC) [4]. The relatively good efficiency and simple programming interface helps TMK remain as the most popular DSM system. On the other hand, Midway adopted an even weaker model called Entry Consistency (EC) [5], but it requires programs to insert explicit statements to state which variables should be guarded by a certain synchronization variable. This makes the programming effort more tedious. Hence, our goal is to find a memory consistency model which achieves both good efficiency and programmability. Scope Consistency (ScC) [6] is the candidate. Scope Consistency is developed by the University of Princeton in 1996. It claims to be weaker than LRC, approaching the efficiency of EC. As the programming interface is exactly the same as that used by LRC, good programmability can be ensured. In ScC, we define the concept of scope as all the critical sections using the same lock. This means the locks define the scopes implicitly, making the concept easy to understand. A scope is said to be opened at an acquire, and closed at a release. We define ScC as below: When a processor Q opens a scope previously closed by another processor P, P propagates the updates made within the same scope to Q. This definition is illustrated in Figure 3. When the processor Q opens the scope by acquiring lock L0, the updates in the same scope by P is propagated to Q. Therefore, b is guaranteed to read 5, the value of y updated by P. However, a is not guaranteed to read 3, since P updates x outside the scope guarded by L0. On the other hand, if LRC is used, a must read 3 since LRC propagates all updates before the closing of lock L0 from P to Q.
As ScC propagates less amount of data, the efficiency increases. And the updates not propagated are usually not needed, since it is usual practice for all accesses of the same shared variable to be guarded by the same lock.
|
|
The Migrating-Home Protocol: A memory coherence protocol specifies how the rules set by the memory consistency model are to be implemented. Different protocols can be adopted for implementing a memory consistency model, leading to different performance. Here we compare four differernt memory consistency models: The
Home-Based Protocol: In the home-based protocol as adopted by JIAJIA
V1.1 [7], a processor is fixed to hold the most up-to-date copy
of every page in shared memory. This processor is known as the
home of the page. Under the home-based protocol, the updates
made by every processor on a page are propagated to the home processor
at synchronization time. The
Migrating-Home Protocol: Though it has been proved [8] that the home-based
protocol is more efficient than the homeless protocol, the fact that
a fixed home may not adapt well to the memory access patterns of many
applications. If the home processor itself never accesses the page,
then the updates made by other processors must be propagated through
the network at synchronization time. If the home can be migrated to
the processor accessing the page, then the updates made by the new home
need not be sent anywhere. Hence we proposed the migrating-home protocol
[9], which allows the home location of a page to be migrated from
a processor when serving a page fault. Details of the protocol
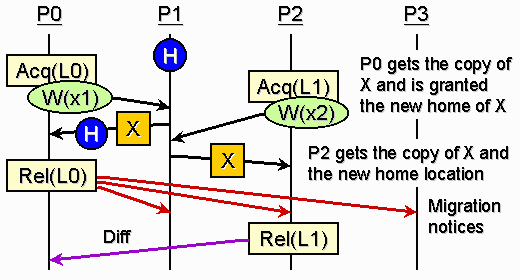
will be discussed later. In our migrating-home protocol, the home of a page X in shared memory is allowed to migrate from processor Q to processor P when Q is serving a remote page fault from P if the following conditions are met: (1) Q is the home of X, and (2) the copy of X held by Q is totally clean, that is, all the other processors having a copy of X have sent the updates to Q. Figure 4 shows how the migrating-home protocol works.
In this example, processor P1 is the original home of page X, specified by the blue token. Under MHP, when P0 writes to variable x1 in page X, it generates a page fault and the request is forwarded to P1, just like any home-based protocol does. However, P1 does not only reply by sending a copy of page X; it also grants P0 as the new home of X, since the conditions for home migration are met. Later, processor P2 writes to x2 in page X. It also generates a page fault for X. P2 does not know the change of home, so it still requests the page from P1. P1, being the previous home, still accepts the request. However, it only sends a copy of page X to P2 without granting P2 the new home, since P1 is no longer the home of X (condition 1). Instead, it tells P2 the new home location, so that P2 can send the updates to the new home P0. The page obtained by P2 is still considered clean, as long as P2 does not access x1. This is reasonable since under LRC or ScC, P2 should not access x1. Otherwise, the result is unpredictable. Next, P0 releases the lock L0. Since P0 is the new home, the updates of x1 need not propagate to other processors. Instead, it sends out migration notices which are short messages (2-4 bytes) telling other processors that the home of X has been changed. The previous home P1 replies this message by telling P0 that P2 has got a copy of X, so P0 can expect P2 may send the updates soon. This information is used to check if the page is allowed to be migrated again if page X is requested. After P1 replies the migration notice, it no longer accepts any request of X, since the new home location should have been well-known. Finally, P2 releases the lock L2 and sends out the updates in the form of a diff. In
this example, if the home-based protocol is used, two diffs will be
involved, one from P0 to P1, the other from P2
to P1. Hence, MHP saves a diff when compared to the home-based
protocol. The tradeoff is the sending of migration notices. Since a
diff records the modification of a page, which is usually much longer
than a migration notice, MHP is able to reduce the network traffic.
We have implemented the migrating-home protocol in the JUMP DSM system. Testing has been conducted on JUMP with various counterparts. The results are shown in the Testing and Results section. |
|
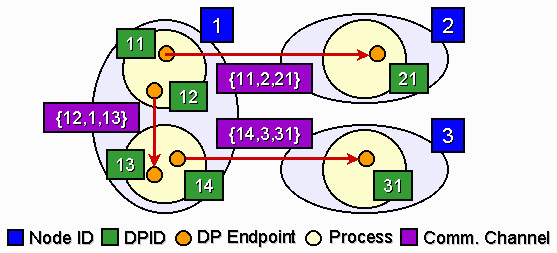
Socket-DP: Network communication is always a source of performance bottleneck in cluster computing like software DSM. There are two software means to relieve the problem. We can either reduce the amount of network traffic, just like what MHP does. Alternatively, we can also speed up the communication by reducing the software protocol overhead. Here we introduce Socket-DP, a low-latency communication package with traditional socket interface to maintain good programmability. Socket-DP captures the design of the Directed Point Model [11], and the features of the model is shown in Figure 5. Each communication endpoint (i.e. socket) is defined by the Node ID, a unique number identfying the machine the endpoint is located; and the DPID, another unique number for identifying different endpoints within a node. A one-way communication channel is then depicted as an edge connecting two nodes, and the whole scenario becomes a directed graph. Each channel is described by the 3-tuple {source DPID, destination NID, destination DPID}.
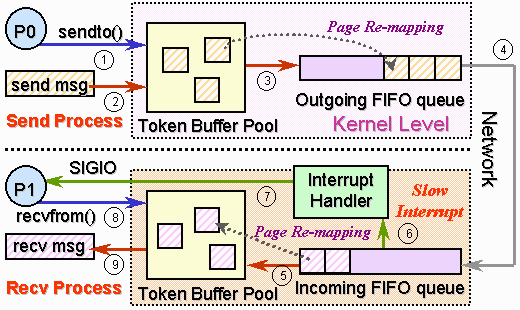
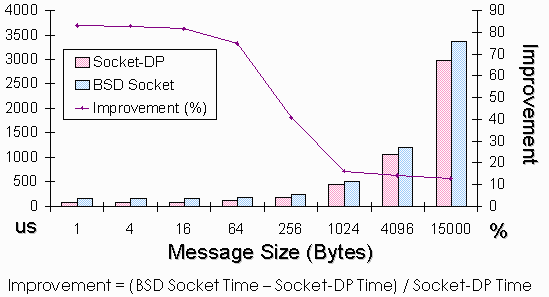
Apart from reducing the latency, Socket-DP also provides several features for enhancing the usability. They are: Asynchronous Communication with SIGIO Handling: Asynchronous sned and receive is used in many DSM systems. A SIGIO signal is delivered to the receiving process on message arrival, so that the receiving process can check the message and handle the request immediately. Message Assembly and Disassembly: Socket-DP implicitly disassembles a long message to be send into packets, so as to accommodate the specification of the underlying network. At the receiver side, the packets received are reassembled back to form the original message without user notice. A Familiar User Interface: The user interface of Socket-DP is closely resembled to that in traditional BSD Sockets. Socket-DP is operated using standard UNIX system calls such as socket(), bind(), sendto(), recvfrom() and select(). We conducted a point-to-point round trip communication test to compare the performance of Socket-DP and traditional BSD sockets. The test is run on 2 Pentium-III 450MHz PCs connected using an IBM Fast-Ethernet switch. The results, shown in Figure 7, show that Socket-DP outperforms BSD Sockets as the protocol overhead is significantly reduced. For messages shorter than 64 bytes, Socket-DP can obtain more than 80% improvement, since the protocol overhead occupies a large portion of the total communication time. For longer messages above 1 KB, Socket-DP is able to improve the performance by about 13-15%.
We ported Socket-DP to JUMP to form the JUMP-DP [12] DSM system. Its performance will be studied in the Testing and Results section.
|
|
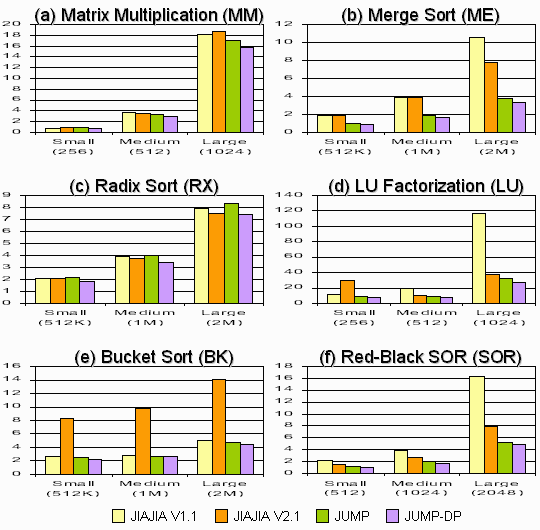
Testing and Results: We have implemented the migrating-home protocol into the JUMP DSM system. It is then further modified to form the JUMP-DP system by embedding the Socket-DP communication support. The two systems are tested by running a suite of 6 benchmark applications. Their execution times are compared with the two versions of JIAJIA, V1.1 and V2.1. JIAJIA V1.1 makes use of the home-based protocol, while JIAJIA V2.1 employs the home migration protocol. By comparing the performance of the four systems, we can have an understanding about the efficiency of the migrating-home protocol as well as the Socket-DP support.
The testing results are shown in Figure 8. Three observations can be obtained:
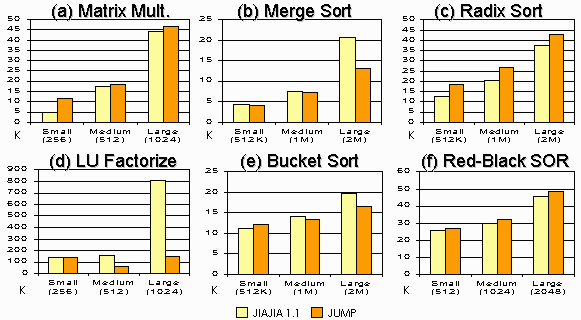
Comparing JUMP with JIAJIA V1.1: The comparison between JUMP and JIAJIA V1.1 shows the difference in performance between MHP and the home-based protocol. From the graphs, it can be seen that JUMP outperforms JIAJIA in 5 out of 6 applications. The only exception is the radix sort program, in which JUMP has a performance degradation of about 15-20%. This shows that MHP favors the memory access patterns of most applications. In the extreme case (LU Factorization), JUMP can run about 3 times faster than JIAJIA. We further study the number of messages and total data volume communicated for each application under JUMP and JIAJIA V1.1. The result is shown in Figure 9. For most applications, JUMP (orange bar) produces more messages than JIAJIA (yellow bar) does. This is due to the broadcast nature of migration notices in MHP. However, the the number of extra messages sent by JUMP grows slower than that by JIAJIA when the problem size increases. This is because MHP takes advantage of the fact that multiple migration notices for different pages can be concatenated as a single message, so as to reduce the communication startup cost.
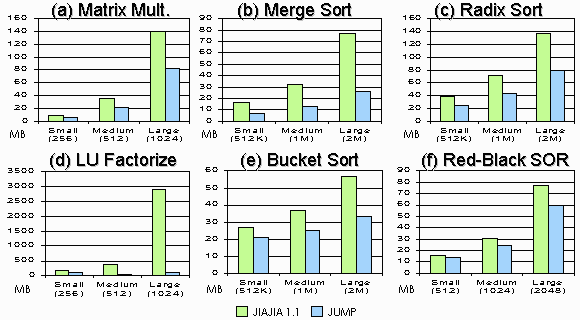
However, when we study the amount of network traffic as Figure 10 shows, we observe that JUMP (blue bar) sends less amount of bytes than JIAJIA (green bar) does in every application. This means the short migration notices in MHP is capable of replacing most lengthy diffs in the home-based protocol, resulting in a reduction in network traffic. The network bottleneck is relieved, and this accounts for the performance improvement in JUMP.
Comparing JUMP with JIAJIA V2.1: The comparison between JUMP and JIAJIA V2.1 shows which of the home migration strategies adapts better to the memory access patterns of the applications. Results from Figure 8 show that although the home migration protocol in JIAJIA V2.1 improves the performance over the home-based protocol in JIAJIA V1.1 for most applications, it is still being outperformed by the MHP in JUMP for 5 out of 6 applications. This means MHP is more efficient than the home-based protocols. In particular, the more aggressive strategy and a wider usage (working on both locks and barriers) accounts for the higher efficiency of MHP. Comparing JUMP-DP with JUMP: The performance comparison between JUMP-DP and JUMP shows us if the low latency Socket-DP support is able to improve DSM efficiency. Results show that the Socket-DP support is able to improve the performance of JUMP steadily in all applications. Most programs enjoy a 5-30% performance improvement. This means DSM can be benefitted by the low-latency communication support. In particular, the existence of many short migration notices and control messages (like lock request and barrier synchronization) favor the use of Socket-DP.
|
|
Conclusions: We have proposed two ways to improve software DSM performance. First, the migrating-home protocol, which is used to implement the scope consistency model, reduces the amount of network traffic for maintaining the memory consistency of the system. Second, Socket-DP, a low latency communication subsystem, reduces the software communication protocol overhead. Our testing shows that the migrating-home protocol is capable of improving the performance of some applications dramatically, while Socket-DP introduces modest performance gain on all applications tested. The two enhancements work together well to improve the performance of DSM applications substantially. We are now working to use JUMP-DP in forming a global object space to support the single system image in the JESSICA2 project.
|
|
References: 1. L. Lamport. How to make a Multiprocessor Computer that Correctly Executes Multiprocess Programs. IEEE Transactions on Computers, C-28(9):690-691, September 1979. 2. J. B. Carter, J. K. Bennett and W. Zwaenepoel. Implementation and Performance of Munin. In Proc. of the 13th ACM Symposium on Operating Systems Principles (SOSP-13), pages 152-164, October 1991. 3. P. Keleher, S. Dwarkadas, A. L. Cox and W. Zwaenepoel. TreadMarks: Distributed Shared Memory on Standard Workstations and Operating Systems. In Proc. of the Winter 1994 USENIX Conference, pages 115-131, January 1994. 4. P. Keleher, A. L. Cox, W. Zwaenepoel. Lazy Release Consistency for Software Distributed Shared Memory. In Proc. of the 19th Annual International Symposium on Computer Architecture (ISCA'92), pages 13-21, May 1992. 5. B. N. Bershad and M. J. Zekauskas. Midway: Shared Memory Parallel Programming with Entry COnsistency for Distributed Memory Multiprocessors. CMU-CS-91-170. 6. L. Iftode, J. P. Singh and K. Li. Scope Consistency: A Bridge between Release Consistency and Entry Consistency. In Proc. of the 8th ACM Annual Symposium on Parallel Algorithms and Architectures (SPAA'96), pages 277-287, June 1996. 7. W. Hu, W. Shi and Z. Tang. A Lock-based Cache Coherence Protocol for Scope Consistency. Journal of Computer Science and Technology, 13(2):97-109, March 1998. 8. Y. Zhou, L. Iftode and K. Li. Performance Evaluation of Two Home-Based Lazy Release Consistency Protocols for Shared Memory Virtual Memory Systems. In Proc. of the 2nd Symposium on Operating Systems Design and Implementation (OSDI'96), pages 75-88, October 1996. 9. B. Cheung, C. L. Wang and K. Hwang. A Migrating-Home Protocol for Implementing Scope Consistency Model on a Cluster of Workstations. In the 1999 International Conference on Parallel and Distributed Processing Techniques and Applications (PDPTA'99), Las Vegas, Nevada, USA. 10. W. Hu, W. Shi and Z. Tang. JIAJIA: An SVM System Based on a New Cache Coherence Protocol. In Proc. of the High-Performance Computing and Networking Europe 1999 (HPCN'99), pages 463-472, April 1999. 11. C. M. Lee, A. Tam and C. L. Wang. Directed Point: An Efficient Communication Subsystem for Cluster Computing. In Proc. of the 10th IASTED International Conference on Parallel and Distributed Computing and Systems, pages 662-665, Las Vegas, October 1998. 12. B. Cheung, C. L. Wang and K. Hwang. JUMP-DP: A Software DSM System with Low-Latency Communication Support. In the 2000 International Conference on Parallel and Distributed Processing Techniques and Applications (PDPTA'2000), Las Vegas, Nevada, USA.
|
|
Technical Papers:
|
|
Research >> JUMP Homepage · JUMP · Research Main ** Main · People · Publications · Facilities · Links |